

واگذاری یک گردشکار پیچیده به هوش مصنوعی مولد

کشفِ یک ظرفیت نوین در ابتدا هیجانانگیز اما کنترلنشده است. اما پس از بلوغ، با «کنترل کردن»، انسان آن را به خدمت میگیرد — نهفقط به عنوان یک ابزار تنها، بلکه به عنوان بخشی از سیستمهای مهندسیشده— وقتی انسان برای نخستینبار با الکتریسیته روبهرو شد، چیزی بیش از یک پدیدهی مرموز و هیجانانگیز نبود؛ جرقهای در شیشه، شوکی روی پوست، یا معلق شدن موهای سر در اثر لمس واندوگراف. سالها طول کشید تا انسان یاد گرفت چگونه این نیروی خام را مهار کند. آن را در سیمها جاری سازد، ولتاژ را کنترل کند و به ابزار قابلاطمینانی برای روشنایی، صنعت و زندگی روزمره بدل نماید. داستان هوش مصنوعی مولد (Generative AI) نیز همین است. در آغاز، ابزاری شگفتانگیز برای بازی با کلمات بود — گپ زدن، شعر گفتن، شوخی کردن یا حتی تقلید نمایشنامهنویسی از روی دست شکسپیر. در بسیاری از کاربردها برای بهرهبرداری محسوس از چنین ظرفیتی، ناگزیریم آن را در معماریهای دقیق، منطقهای مهندسیشده و مسیرهای تصمیمگیری قرار دهیم تا بتواند مسائلی واقعی را با کیفیتی واقعی حل کند.
ما در ترب، همین مسیر را پیش گرفتیم تا یکی از پرچالشترین دغدغههای کاربران را به شیوهای هوشمند پاسخ دهیم: پیگیری سفارش!
این نوشته دربارهی راهکارهایی است که با استفاده از هوش مصنوعی مولد ما را قادر ساخت تا مسئولیت چالشبرانگیز حلوفصل پیگیریهای ثبتشده توسط کاربران را با دقت بالای ۹۰ درصدی به صورت خودکار انجام دهیم.
پیگیری سفارش در ترب
ترب یک موتور جستجوی خرید است که با استفاده از آن کاربر میتواند محصول مورد نظر خود را پیدا کرده و آن را از ارزانترین فروشنده خریداری کند. اما کار ترب در همینجا به پایان نمیرسد و در صورتی که کاربر به هر دلیلی در فرایند خرید خود از فروشگاه دچار مشکل شود (مثلا کالا معیوب یا متفاوت ارسال شود یا هر مشکل دیگر) میتواند در ترب درخواست پیگیری ثبت سفارش ثبت کند. این درخواست توسط کارشناسان ترب مورد بررسی قرار میگیرد و ترب سعی میکند، با مداخله مناسب و بهینه مشکل پیش آمده بین فروشگاه و کاربر را حلوفصل نماید.
همچنین ترب از این اطلاعات به منظور تشخیص فروشگاههای با کیفیت خدمات پایین استفاده میکند تا در ادامه همکاری خود را با این فروشگاهها کاهش داده و در صورت عدم حل مشکلات توسط آنها به صورت کامل با این فروشگاهها قطع همکاری نماید.
آنچه رسیدگی به درخواستهای پیگیری سفارش را سخت میکند،نیاز به نیروی پشتیبانی زیاد برای بررسی و تعیین وضعیت درخواستها است. این تعداد زیاد نیروی انسانی، هم به خاطر ذات مسئلهی پیگیری سفارش است که ممکن است بیش از یک بار برای هر پیگیری مداخلهی کارشناس را بطلبد و هم به خاطر رشد پیگیریهای ثبت شده در ازای رشد بازدیدها و به تبع آن رشد خریدها. تا جایی که در حال حاضر، روزانه حدود ۱۰۰۰ هزار پیگیری سفارش در ترب ثبت میشود که میتواند فرایند مقیاسپذیری را به نقطهی بحران برساند.
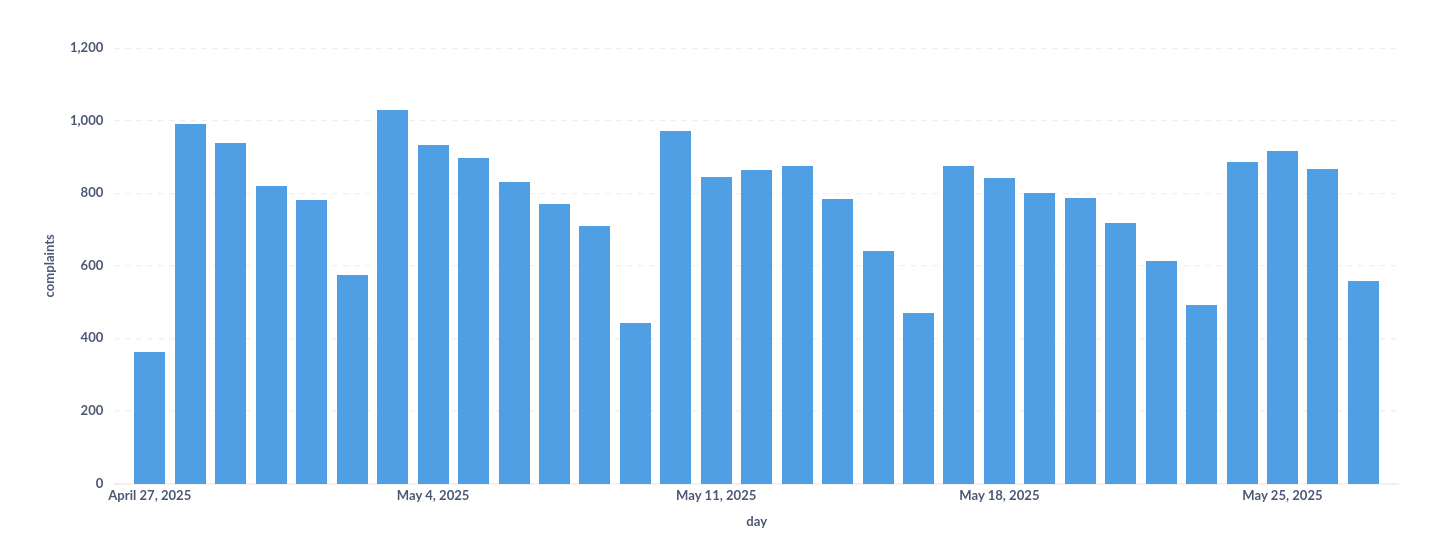
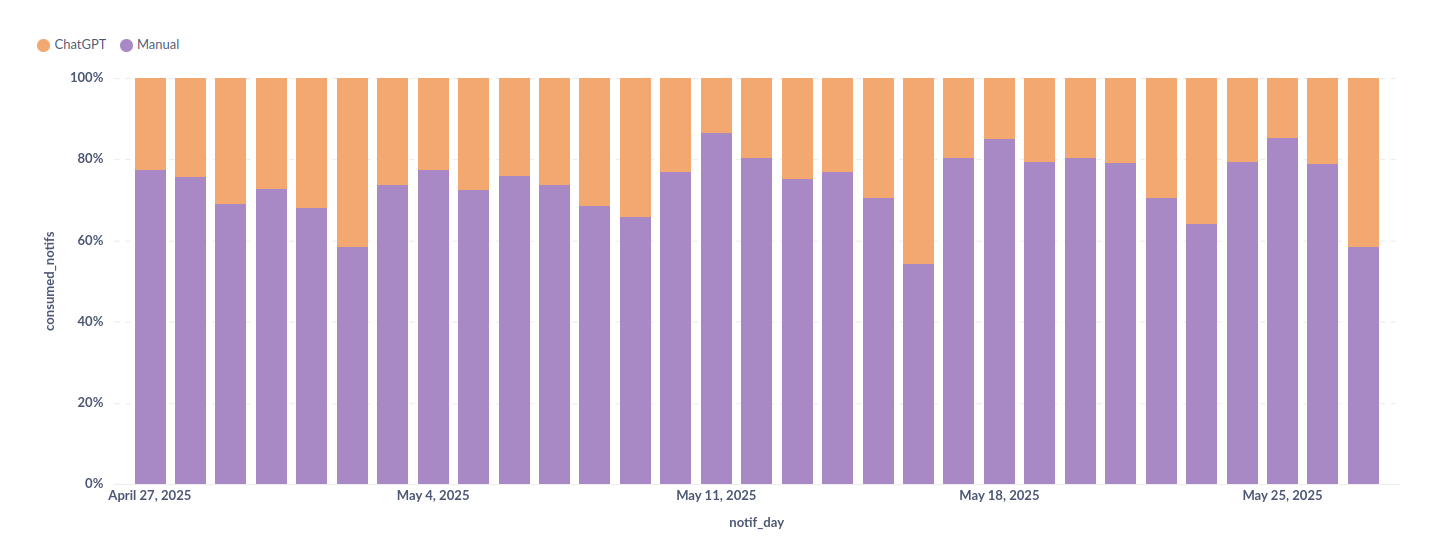
در همین رابطه، یکی از اصلیترین مزیتهای یک کسبوکار در رقابت بر سر مقیاسپذیری و گرفتن سهم بیشتر از بازار، این است که زیرسیستمهای یک کسبوکار تا چه حد مقیاسپذیر هستند. کسبوکاری که افزایش ورودی آن (مثلاً کلیک، سفارش، یا تعامل کاربر) الزاماً نیازمند افزایش متناسب در منابع انسانی، زمان پردازش یا هزینههای عملیاتی باشد، رشد سیستم را از نقطهای به بعد منوط به رشد زیر سیستمی میکند که گلوگاه شده است. مثلا اگر تعداد منابع انسانی پشتیبانی شکایت به صورت خطی با بیشتر شدن تعداد پیگیریها در ازای رشد بازدیدها، نیاز به رشد داشته باشد، این مسئله محتمل خواهد شد که هزینهی پشتیبانی به آوردهی رشد غلبه کند. برای همین، وقتی از خودکار کردن فرایند رسیدگی به پیگیری سفارشها ثبتشده صحبت میکنیم، این کار باید به گونهای باشد که هم کیفیت بررسیها حفظ شود و هم بار قابلتوجهی را از روی دوش تیمم عملیات و پشتیبانی کم کند. در حالت ایدهآل نیروهای پشتیبانی مورد نیاز برای بررسی این درخواستها در یک روز، باید مقداری ثابت و مستقل از تعداد پیگیری سفارشها داشته باشد. یعنی حتی اگر یک روش خودکار کردن بسیار دقیق داشته باشیم که نیمی از کارها را انجام دهد و نیمی دیگر را برای کارشناس انسانی باقی بگذارد، اگرچه باز هم تاثیر بسیار خوبی دارد ولی باز هم تامین نیروی عملیات، یکی از موانع رشد در مقیاس بزرگ خواهد بود. آنچه ما در ترب انجام دادهایم اگرچه هنوز با چنین وضعیت ایدهآل فاصله دارد، اما توانسته ۶۸ درصد مداخلات در تیکت را بدون نیاز به کارشناس پشتیبانی انجام دهد و تنها در ۳۲ درصد مداخلات به کارشناس انسانی نیاز بوده است. همچنین در مداخلاتی که به صورت خودکار انجام شده، در ۹۲ درصد موارد تصمیم درست گرفته شده است.
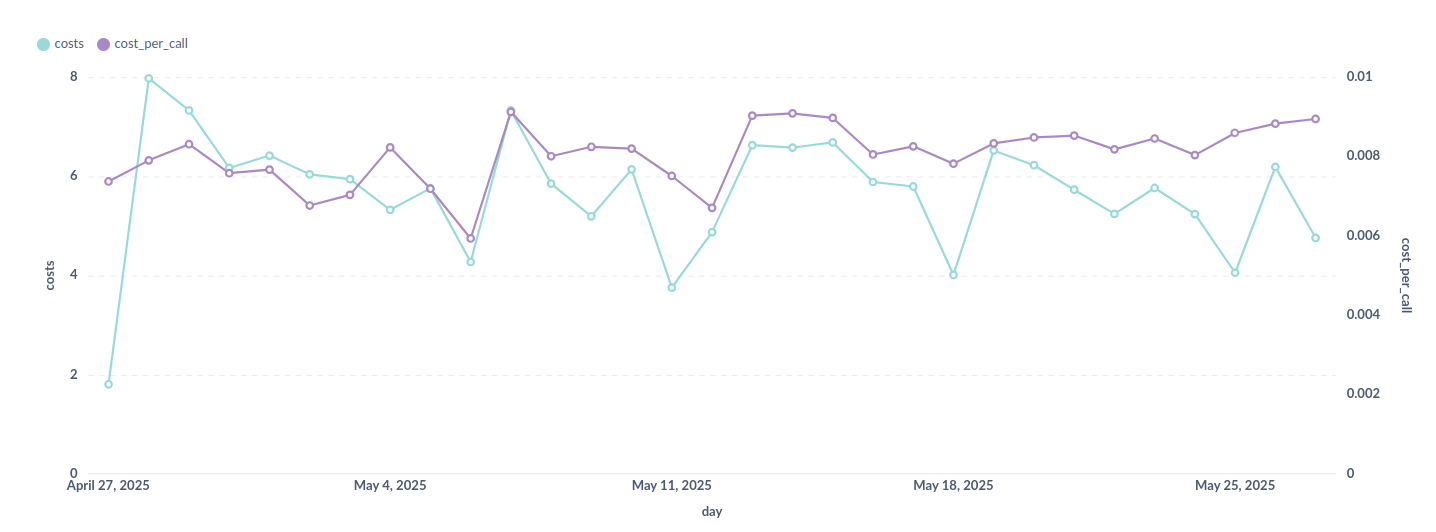
البته این آمار و ارقام مربوط به یک دادهی طلایی ۱۰۰ تایی از پیگیری سفارشهای بسته شده مربوط به یک ماه پیش از نگارش این متن است؛ بررسی خودکار هنوز در همهی انواع پیگیریهای سفارش در ترب فعال نشده و به همین خاطر میزان تاثیر در مقایسه با همهی پیگیریهای سفارش، هنوز با این ارقام فاصله دارد. در حال حاضر به ازای ۶ دلار هزینهی روزانه، ۲۰ تا ۳۰ درصد مداخلات در تیکت به صورت خودکار انجام میشود.
تعریف مساله و بیان راهحل
برای درگیر شدن در طراحی راهحل، خوب است یک بار ورودی مسئله و خروجی مطلوب را مرور کنیم. کاربر با ثبت پیگیری، مشکلی که با آن مواجه شده را توضیح میدهد و یک تیکت پیگیری سفارش برای فروشگاه ایجاد میکند که از طریق آن، کاربر و فروشگاه میتوانند در حضور کارشناس پشتیبانی شکایت، تا رفع مشکل با هم گفتوگو کنند. دنیا خیلی جای بهتری میشد اگر بدون نیاز به مداخلهی کارشناس، این تیکتها حلوفصل میشد اما تجربه نشان داده که رها کردن تیکتها، اغلب منجر به رفع مشکل نمیشود. پس خروجی مطلوب، در یک سطح بالاتر از انتزاع، این است که پیگیری سفارشها منجر به حل مشکل کاربر شوند و در یک سطح پایینتر، این است که مواقع مداخلهی کارشناس و جزئیات مداخلات او را مشخص کنیم. در خصوص جزئیات مداخله، اختیارات کارشناس شامل نوشتن یک متن درون تیکت، غیرفعال کردن فروشگاه در ترب، خاتمه دادن تیکت با تعیین میزان تخلف فروشگاه و زمانبندی بعدی برای بررسی مجدد تیکت میشود. در واقع زمانبندی بعدی برای بررسی مجدد تیکت، برای فرار از مسئلهی سختِ جستوجو بین همهی زمانهای ممکن برای مداخله، قرار داده شده است و به طور شهودی بهینگی پاسخ را هم متاثر نمیکند؛ به بیان دیگر، این که از بین همهی زمانهای ممکن برای مداخله در تیکت، لحظهبهلحظه تیکت را زیر نظر بگیریم تا مواقع مداخلهی بهینه را تعیین کنیم، فرق زیادی ندارد با اینکه بعد از اولین مداخله، زمان مداخلهی بعدی را با توجه به مواردی که از طرفین خواستهایم تعیین کنیم. تنها منشا عدم دقت، اتفاقاتی است که تا مداخلهی بعدی از آنها بیخبر خواهیم ماند. چنانچه مسئله واضح است، میتوانید پیش از ادامه، در خصوص راهحل پیشنهادی خود فکر کنید.
برای بهکارگیری مدلهای زبانی بزرگ در خودکارسازی فرایند پیگیری سفارش در ترب، سادهترین راه، استفادهی مستقیم از این مدلها برای تولید پاسخ (بهصورت سرتاسری) است. در این روش، کافیست رشتهی مکالمات موجود در تیکت را به مدل بزرگ زبانی (مثلا gpt-4o) بدهیم و از آن بخواهیم با توجه به محدودهی اختیارات، مستقیماً تصمیمگیری کند. یعنی به محض ایجاد تیکت توسط فروشگاه، متن را مثلا به gpt-4o میدهیم و میخواهیم که در یک پاسخ ساختارمند، پیام لازم، وضعیت تیکت (از بین یک سری گزینهی از پیش تعریف شده) و زمان (احتمالی) بعدی برای بررسی مجدد تیکت در صورتی که در این بررسی قصد خاتمهی آن را ندارد را تعیین کند.
این روش، علاوه بر سادگی پیادهسازی، بیشترین انعطافپذیری را در مواجهه با پیشامدهای غیرمنتظره فراهم میکند. اما موانع مهمی در مسیر استفاده از آن وجود دارد؛ مهمترین آن، غیرقابلپیشبینی بودن خروجی است. یک مدل بزرگ زبانی، ممکن است تصمیماتی بگیرد که با سیاستهای تیم پشتیبانی در مدیریت شکایات و درخواستهای پیگیری سفارش همخوانی نداشته باشد.
توجه به همین «سیاستها» سرنخ راهحلهای بعدی را در خود دارد. در واقع، کارشناسان پشتیبانی شکایات، مجموعهای از راهبردهای ذهنی برای هدایت شکایتها به سمت حلوفصل در اختیار دارند که هر سیستم خودکار باید با آنها همراستا باشد. وجود چنین راهبردهایی برای کنترل خروجی تولید شده، استفاده از معماری RAG (بازیابی و تولید) را به ذهن متبادر میکند. یعنی ابتدا راهبردهای موجود در مدیریت شکایات مستندسازی میشوند. سپس این مستندات بهعنوان منبع بازیابی در اختیار سیستم قرار میگیرند. سیستم، با توجه به مکالمات ثبتشده در تیکت، ابتدا بخش مرتبطی از مستندات را «بازیابی» میکند و سپس این اطلاعات را به مکالمهی انجام شده افزوده و متن «افزوده» شده را به مدل زبانی وارد میکند تا پاسخ نهایی «تولید» شود.
این رویکرد، در مقایسه با تولید سرتاسری، بسته به کیفیت و دقت بازیابی، قابلیت کنترلپذیری بیشتری فراهم میکند. با این حال، همچنان احتمال بروز خروجیهای غیرقابلپیشبینی وجود دارد، بهویژه اگر فرایند بازیابی شفاف و قابل تحلیل نباشد. نقطهی کلیدی در این کاربرد از معماری RAG، مرحلهی بازیابی است. هرچه این مرحله قابل پیشبینیتر و تفسیرپذیرتر باشد، کنترل بیشتری بر رفتار سیستم خواهیم داشت. اگر ندانیم که چگونه یک بخش خاص از مستندات بازیابی میشود، نمیتوانیم محاسبه کنیم که برای ایجاد یک تغییر موردنظر در خروجی، کدام بخش از مستندات را باید ویرایش کنیم و این ویرایش به چه شکل باشد. در مقابل، اگر فرایند بازیابی قابل تحلیل باشد، میتوان با اصلاح مستندات، پاسخهای مدل را نیز به شکل هدفمند کنترل کرد.
یکی از راههای منطقی برای ساخت یک ساختار بازیابیپذیر، مدلسازی فرایند رسیدگی به شکایتها به شکل گراف جهتدار تصمیمهاست. منظور از فرایند رسیدگی، دنبالهی تصمیمات و اقدامات کارشناس پشتیبانی در مواجهه با تیکت است. اگر فرض کنیم که هر تصمیم کارشناس در یک لحظهی مشخص از زمان و با توجه به وضعیت تیکت اتخاذ میشود، آنگاه مسیر رسیدگی را میتوان بهصورت یک دنبالهی گرهها و یالها مدل کرد. برای مثال، در اولین بررسی یک تیکت، کارشناس بر اساس محتوای مکالمات اقدامات خاصی انجام میدهد. اگر مسئله در همان مرحله حل شود، پیگیری خاتمه مییابد. در غیر این صورت، تیکت در زمان دیگری دوباره به مداخلهی کارشناس نیاز پیدا میکند. اگر چه که ممکن است در هر بار ورود کارشناس به تیکت، وضعیتهای بسیار متنوعی بروز کرده باشد، انتظار میرود اگر این وضعیتها را برحسب وضعیت قبلی دستهبندی کنیم، حالتهای پرتکرار انگشتشمار باشند. مثلا در دومین مداخلات کارشناسها در تیکتهای پیگیری سفارش، اتفاقات بسیار متنوعی ممکن است رخ داده باشد اما اگر فقط آن مداخلاتی را در نظر بگیریم که در مداخلهی قبلی، کارشناس از فروشگاه مثلا خواسته که کد رهگیری مرسوله را ارسال کند، پیشامدهای پرتکرار زیاد نخواهند بود. اگر مدلسازی گراف بهگونهای باشد که افزودن وضعیتهای جدید (یعنی پیشامدهای تازه) بهسادگی امکانپذیر باشد، میتوان به مرور زمان گراف را تکمیل کرد و از رفتار سیستم در مواجهه با موقعیتهای جدید اطمینان بیشتری حاصل کرد.
پس از طراحی گراف، کاری که باقی میماند، تشخیص وضعیت فعلی تیکت و انتخاب یکی از گزینههای از پیش تعریفشده (یعنی یالهای خروجی از گره فعلی) با توجه به متن مکالمات است. به این ترتیب، مسئلهی پیچیدهی تصمیمگیری در پیگیری سفارش به یک مسئلهی انتخاب پاسخ از بین گزینههای محدود بر اساس متن تبدیل میشود.
این پیادهسازی از نظر مفهومی نیز تفکیک معناداری ایجاد میکند. بخشی از مهارتهای کارشناس پشتیبانی مربوط به درک زبان فارسی است که این وظیفه را میتوان به مدل زبانی سپرد. بخش دیگر، مهارتهای تخصصی در هدایت شکایت است که بهصورت ساختارمند در گراف جهتدار ذخیره میشود. به این ترتیب، نقش مدل زبانی صرفاً تحلیل متن و انتخاب بین گزینهها خواهد بود و بخش حساس راهبردی، تحت کنترل کامل باقی میماند. نکتهی دیگر اینکه نرخ تغییرات در گراف تصمیمات، احتمالا باید کم باشد. در واقع نرخ تغییرات کم، معادل با ثبات سیاستهای پیگیری سفارش در ترب است؛ پس واگذاری آن برای تغییرات پیدرپی به هوش مصنوعی، چندان کارآمد هم نخواهد بود.
جزئیات پیادهسازی
علیرغم وجود ابزارهای آماده برای پیادهسازی چنین سیستمی، پیادهسازی آن از ابتدا، کار سختی نیست. اگر چه که معماری پیاده شده که در ادامه به آن اشاره میشود مربوط به سیستمی است که مسئول خودکار کردن پیگیریهای سفارش کاربر در ترب است، اما سعی شده تا اسامی و توضیحات به صورت عامتری بیان شوند تا محدود به چنین سیستمی نباشند.
مسئلهی خودکار کردن رانندگی را در نظر بگیرید؛ مطمئنا ممکن بود که از همان ابتدا، طراحی را در چنین خودروهایی به شکلی تغییر بدهند که رابطهایی به اسم فرمان و پدال گاز و پدال ترمز نداشته باشند و سامانهی هوشمند، به طور مستقیم به جعبه فرمان و کنترلکنندهی انژکتور و دیسکهای ترمز متصل باشد. اما چنین چیزی مشاهدهپذیری سیستم را کم میکند و این (حداقل در ابتدای راه) خطرناک است. وجود رابطهایی مثل پدال گاز و ترمز این قابلیت را میدهد که عملکرد سامانهی هوشمند تحت اشراف ما باشد و مهمتر اینکه بتوان آن را به محض اراده تصحیح کرد. بدون این نشانهها، راننده یا ناظر انسانی «کور» میشود؛ یعنی نمیفهمد سیستم چه کاری میکند یا قرار است بکند. حتی اگر متوجه شود که سیستم اشتباه عمل میکند، نمیتواند دخالت کند.
در مسئلهی خودکار کردن بررسی پیگیریهای کاربران هم خوب است که ابتدا معماری را برای بررسی دستی طراحی کنیم و سپس اقدام به خودکار کردن تصمیمگیریها کنیم. آنچه در ادامه از ساختار موجودیتها میآید، فرم ساده شدهای از پیادهسازی واقعی در ترب است.
class DecisionOption {
+Text condition_text
+Enum activation_state
+FK primaryـconsequence: class
+FK secondaryـconsequence: class
+Array<Integer> evaluation_data
+M2M next_options: DecisionOption
}هر نمونهای از این کلاس، به ترتیب یک متن دارد که شرایط آن وضعیت را توصیف میکند. activation_state وضعیت فعال بودن این گزینه را تعیین میکند. این برای کم و زیاد کردن موقت گزینهها لازم است. پیامدهای انتخاب گزینه (یعنی همین موارد primaryـconsequence و secondaryـconsequence و سایر پیامدها) بسته به کاربرد میتوانند متنوع باشند. هم از نظر تعداد و هم از نظر نوع. مثلا ما در DecisionOptionها پیامدهایی داریم که وضعیت تیکت را بلافاصله بعد از انتخاب آن گزینه تعیین میکنند. همینطور پیامدهاییکه تعیین میکنند تیکت چه زمانی دوباره باید توسط سیستم بررسی شود. و همینطور اینکه چه پیامی در تیکت ارسال شود. این پیامدها ممکن است نیاز به دادههای دیگری برای ذخیره کردن در مدل داشته باشند. از این دادهها که بگذریم، یک نکتهی مهم این است که صرفنظر از این که از همان ابتدا سیستم به طور خودکار اجرا میشود یا نه، خوب است که evaluation data جمعآوری کنیم. یعنی تعدادی از انتخابهای درست آن گزینه (به صورت دستی یا خودکار) را طول زمان جمعآوری کرده باشیم تا در آینده بتوانیم ارزیابی درستی از انتخاب خودکار و مقایسه روشهای مختلف داشته باشیم. هر چه این انتخابهای درست، تنوع بیشتری از ورودیها را داشته باشند، ارزیابی قابل اتکاتر است. در آخر مهم است که اگر مسئله دوباره به دست ما برگشت، برای پیشامدهای مختلف پیشبینی داشته باشیم. این پیشبینیها، گزینههای بعدی گراف در next_options را میسازد.
تا اینجا، مسئله قابل پیادهسازی و استفاده به صورت دستی است. برای خودکار کردن این تصمیمگیریها، خوب است که یک موجودیت مجزا تعریف کنیم.
class DecisionHandler {
+Enum decision_agent
+Text conditions_prompt
+Boolean is_active
+Boolean evaluated
+Float review_rate
+JSON evaluation_result
+FK decision_option: DecisionOption
}هر موجودیت تصمیمگیری خودکار، برای خودکار کردن پاسخ به یکی از سوالات در فرایند بررسی پیگیری سفارش ایجاد میشود. البته ممکن است یک سوال مشخص، چندین عامل خودکار کننده داشته باشه، منطقی است که بهترین آنها صرفا فعال باشد و تصمیمات را بگیرد. عامل تصمیمگیری میتواند یک مدل بزرگ زبانی که به صورت عمومی قابل دسترسی است باشد، یا یک شبکهی عمیق آموزش داده شده برای تسک پاسخدهی به سوال چندگزینهای. decision_agent هر چه باشد، متن مکالمه به همراه conditions_prompt از او پرسیده میشود و پس از ارزیابی روی evaluation_data آن سوال، evaluation_result تعیین میشود. استراتژی فعال کردن موجودیتهای تصمیمگیری خودکار از بین همهی موجودیتهای ارزیابی شده برای یک سوال، بسته به کاربرد میتواند فرق کند.
به این ترتیب چرخهی توسعهی سیستم به این صورت میشود که پس از ساخت DecisionOptionها، کافی است سیستم را به صورت دستی استفاده کنیم و با مانیتور کردن مواقعی که عامل انسانی گزینهی هیچکدام را انتخاب کرده، پوشش گراف را روی پیشامدهای محتمل تا حد ممکن بالا ببریم. سپس با دستچین کردن انتخابهای متنوع کارشناس در هر سوال، دادهی ارزیابی برای آن سوال فراهم میکنیم و در نهایت با استفاده از دادههای ارزیابی، متن پرامپت را تا دقت مطلوب تنظیم میکنیم.
دورنمای کوپایلت تیکتینگ در ترب
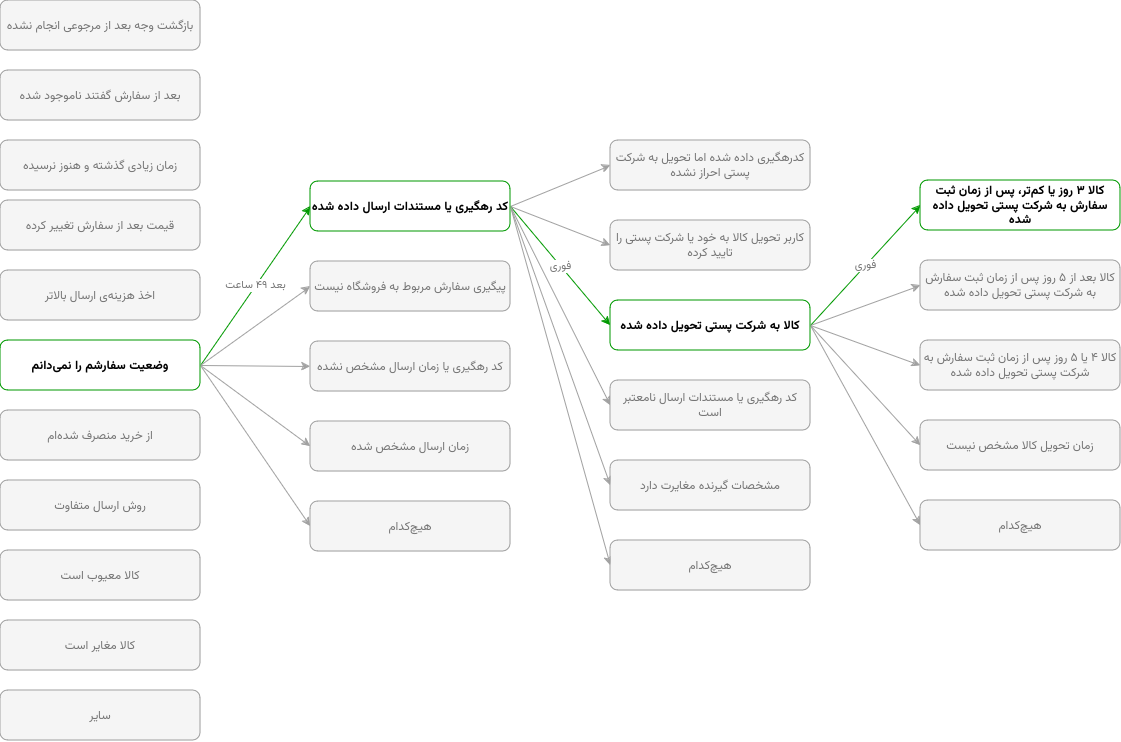
پیگیریهای سفارش در ترب، بر حسب موضوع پیگیری دستهبندی شدهاند. برای مثال، اگر کاربر به خاطر عدم اطلاع از وضعیت سفارش، پیگیری ثبت کرده باشد، موضوع پیگیری «وضعیت سفارشم را نمیدانم» خواهد بود. در خصوص همین مثال، راهبرد تیم پشتیبانی برای حلوفصل تیکت این است که پیام زیر به فروشگاه ارسال شود و تیکت مجدد ۲ روز بعد بررسی شود:
همکار محترم
ضمن عرض سلام و احترام،
با توجه به درخواست مشتری در این پیگیری سفارش، خواهشمندیم در اسرع وقت به شرح زیر اقدام فرمایید:
در صورت ارسال کالا:
برای انجام بررسیهای خودکار، لطفاً کد رهگیری مرسوله را به صورت تایپ شده در متن تیکت درج فرمایید.
تصویری واضح از صفحه استعلام وضعیت مرسوله از طریق درگاه رسمی شرکت حملونقل (با نمایش واضح کد رهگیری و تاریخ و ساعت آخرین بهروزرسانی) را ضمیمه کنید.
در صورت عدم ارسال کالا:
حتما تاریخ و ساعت دقیق تحویل کالا به مرکز حملونقل را به صورت دقیق در این تیکت قید نمایید.
توجه داشته باشید در صورت حل مشکل کاربر در ۴۸ ساعت، هیچ امتیازی از شما کسر نخواهد شد.
حالا بعد از گذشت ۴۸ ساعت، برحسب اتفاقات گوناگونی که ممکن است در تیکت افتاده باشه، یکی از حالتهای زیر متصور است:
- کد رهگیری یا مستندات ارسال داده شده
- پیگیری سفارش مربوط به فروشگاه نیست
- کد رهگیری یا زمان ارسال مشخص نشده
- زمان ارسال مشخص شده
- هیچکدام
تشخیص اینکه کدام یک از این پیشامدها رخ داده، میتواند توسط هر عامل هوشمندی که زبان طبیعی را میفهمد انجام شود. مثلا اگر فروشگاه تصویر رهگیری مرسوله در سایت پست را ضمیمه کرده باشد، گزینهی «کد رهگیری یا مستندات ارسال داده شده» انتخاب میشود که در اثر انتخاب آن، گزینههای زیر بلافاصله از عامل تصمیمگیرنده پرسیده میشود:
- کدرهگیری داده شده اما تحویل به شرکت پستی احراز نشده
- کاربر تحویل کالا به خود یا شرکت پستی را تایید کرده
- کد رهگیری یا مستندات ارسال نامعتبر است
- کالا به شرکت پستی تحویل داده شده
- مشخصات گیرنده مغایرت دارد
- هیچکدام
توضیحات این گزینهها –که در واقع همان conditions_text در توضیحات بالا هستند– در بررسیهای خودکار، در conditions_prompt شرح داده میشود. حالا با فرض وجود تصویر رهگیری مرسوله در سایت پست، گزینهی «کالا به شرکت پستی تحویل داده شده» انتخاب خواهد شد که در ازای این انتخاب، گزینههای زیر بلافاصله پرسیده میشود:
- کالا ۳ روز یا کمتر، پس از زمان ثبت سفارش به شرکت پستی تحویل داده شده
- کالا بعد از ۵ روز پس از زمان ثبت سفارش به شرکت پستی تحویل داده شده
- کالا ۴ یا ۵ روز پس از زمان ثبت سفارش به شرکت پستی تحویل داده شده
- زمان تحویل کالا مشخص نیست
- هیچکدام
در این مرحله عامل هوشمند باید سعی کند از روی تصویر داده شده تشخیص دهد که کالا چند روز پس از سفارش به شرکت پستی تحویل داده شده است. مثلا در حالتی که کالا ۳ روز یا کمتر، پس از زمان ثبت سفارش به شرکت پستی تحویل داده شده باشد، تیکت خاتمه مییابد و امتیازی هم از فروشگاه کسر نمیشود.
چنین ساختاری، نه فقط برای پشتیبانی شکایات، بلکه در هر فرایندی که اولا گردشکار نسبتا با ثباتی دارد و ثانیا با مشخص شدن گردشکار، انتخاب بین پیشامدهای مختلف آن ساده است، قابل پیادهسازی است و به نظر میرسد سختی ساخت تدریجی گراف مربوط به گردشکار، ارزش کنترلپذیری آن را داشته باشد. هر چند اگر دادههای کافی در خصوص تصمیمات دستی در سیستم آماده باشد، روشهای خودکاری برای بازیابی گردشکار وجود دارد که میتواند برای ساخت گراف در ابتدای ماجرا از آنها استفاده کرد.
فرصتهای شغلی ترب
اگر به تکنولوژیهای نوآورانه علاقه دارید و دوست دارید در توسعه یک موتور جستجوی خرید پیشرو نقش داشته باشید، تیم مهندسی ترب به دنبال افراد باانگیزه و خلاق است!
مشاهده فرصتهای شغلی
داستان جابجایی ۱۸ سرور ترب در بامداد ۱۰ شهریور ۱۴۰۲
بهروزرسانی پایگاهدادهی اصلی ترب
مسیر ساخت WAF در ترب؛ نگاهی به چالشها و تجربههای بهدست آمده