

مسیر ساخت WAF در ترب؛ نگاهی به چالشها و تجربههای بهدست آمده
روزانه تعداد زیادی درخواست خودکار از رباتها به سمت ترب ارسال میشود. بعضی از این درخواستها، درخواستهای مفیدی هستند. برای مثال درخواستهایی که از سمت گوگل میآید جزء درخواستهای مفید هستند. از طرفی بعضی از این درخواستها ناخواسته و در دستهی مضر قرار میگیرند. برای مثال بعضی از رباتها اقدام به فراخوانی درگاهها ارسال رمز عبور میکنند. این کار علاوه بر اعمال هزینههای اضافه باعث نارضایتی از سمت شمارهی مقصد میشود. به همین جهت نیازمند روشهایی برای جلوگیری از این درخواستهای خودکار داریم. در عین حال نباید مانع کار رباتهای مفید شویم. برای این کار نیازمند سیستمی برای تشخیص و اعمال محدودیت روی درخواستها هستیم.
معماری سیستم
هدف و نیازمندی اصلی سیستم جلوگیری از انجام درخواستهای نامعتبر است. در ترب برای رسیدن به این هدف سیستمی با معماری کلی زیر را توسعه دادیم:

در ابتدا تمام Access Log ها برای Access Log Collector ارسال میشود. این Access Log توسط این سیستم غنیتر میشوند. برای مثال کشور مربوط به IP اضافه میشود. سپس در دو دیتابیس ذخیره میشود. سرویس Bot Detector به صورت مدام در حال بررسی Access Log ها است. در صورتی که مورد مشکوکی را تشخیص دهد پیامی را برای Blocker ارسال میکند. سپس Blocker براساس این پیام درخواستها رو محدود میکند یا مانع انجام آنها میشود.
در ابتدا از elasticsearch برای ذخیره access log ها استفاده میکردیم. bot detector اطلاعات درخواستها را از روی elasticsearch برمیدارد و مورد بررسی قرار میدهد. در ادامه به دلیل این که کار با clickhouse راحتتر بود و منابع کمتری مصرف میکرد یک نسخه از access log ها در این پایگاهداده ذخیره میشود. صرفاً دادههای یک روز اخیر در elasticsearch ذخیره میشود و برای backward compatible نگهداشتن elasticsearch همچنان در مدار قرار دارد.
تمرکز اصلی این مطلب بر روی قسمت Blocker است. در ادامه این قسمت را با جزئیات بیشتری مورد بررسی قرار میدهیم. سایر قسمتها مثل bot detector و access log collector خارج از محدودهی این مطلب است و زیاد در مورد آن صحبت نمیکنیم.
تاریخچه
به صورت کلی اتصالات شبکه در ترب به صورت زیر است:

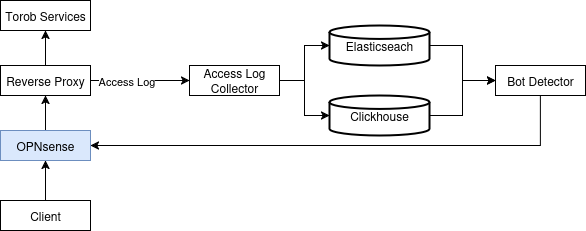
در ابتدا از OPNsense به عنوان «فایروال» (firewall) استفاده میکردیم. OPNsense یک سیستمعامل متنباز و مبتنی بر FreeBSD است. این سیستمعامل برای راهاندازی فایروال، Router و سامانههای امنیتی شبکه طراحی شده است. این سیستمعامل یک API برای تنظیم کردن بخشهای مختلف سیستم در اختیار ما قرار میداد. با استفاده از این API میتوانستیم یک تعداد IP را بلاک کنیم. در نتیجه در ابتدا، سیستم کلی به شکل زیر بود:
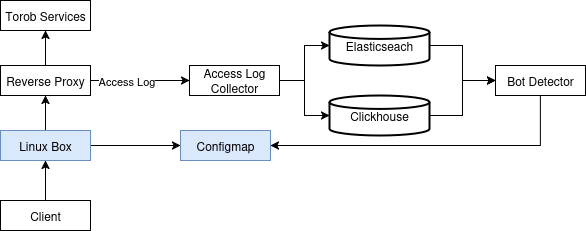
بعد از مدتی با توجه به آشنایی بیشتر با سیستمعاملهای مبتنی بر Linux، استفاده از OPNsense را متوقف کردیم. به جای OPNsense از سیستمعامل Ubuntu استفاده کردیم. در این حالت Bot Detector آدرس IP مواردی را که تشخیص میداد در داخل یک ConfigMap داخل کلاستر kubernetes ذخیره میکرد. فایروال جدید به صورت دورهای این IP ها را دریافت میکرد. سپس با استفاده از iptables اقدام به بلاک کردن ترافیک با آدرس مبدا این IP ها میکرد. سیستم به صورت کلی به شکل زیر تغییر کرد:
در ادامه این معماری با مشکلاتی رو به رو شد:
برای block کردن، iptables به صورت خطی قوانین را بررسی میکرد. در نتیجه در مقابل syn flooding آسیبپذیر بودیم. دیتابیس قوانین به حدود ۵۰ هزار قانون رسیده بود. در نتیجه به ازای هر بار باز شدن connection در بدترین حالت هر ۵۰ هزار قانون باید بررسی میشد. البته میشد از پروژههایی مثل ipset برای حل این موضوع استفاده کرد. منتهی این تنها مشکل نبود.
قوانین فایروال در لایهی ۳ شبکه اعمال میشدند. بنابراین کاربر هیچ اطلاعی در مورد وضعیتش نداشت. به عبارت دیگر نمیدانست که مشکل از شبکه خودش است یا مشکل از block شدن توسط فایروال است. این مسئله حل و تشخیص مشکلات را برای خودمان را هم سختتر کرده بود.
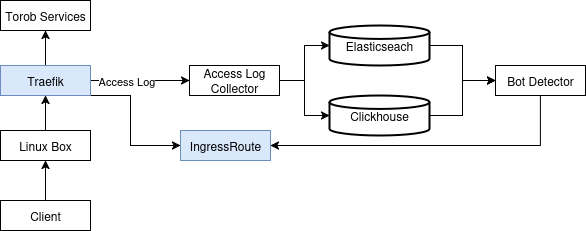
در نتیجه تصمیم گرفتیم که این قوانین را به لایهی ۷ منتقل کنیم. چون در آن زمان از Traefik به عنوان Reverse Proxy استفاده میکردیم. تصمیم گرفتیم که از همین Traefik برای block کردن درخواستها نیز استفاده کنیم. همچنین به جای block کردن بهتر بود یک صفحهای به کاربر نمایش بدهیم تا کاربر با حل یک challenge بتواند مجدد فعالیت خود در ترب را ادامه دهد. نیازمندی دیگر این بود که این تغییر منجر به کاهش سرعت پردازش درخواستها نشود.
پیادهسازی را به این طریق انجام دادیم که یک IngressRoute جدید برای Traefik اضافه کردیم و داخل قسمت match این Route، قوانینی که برای محدود کردن داشتیم قرار دادیم. برای مثال:
apiVersion: traefik.io/v1alpha1
kind: IngressRoute
metadata:
name: block
namespace: test
spec:
routes:
- kind: Rule
priority: 999999
match: ClientIP(`1.1.1.1`, `2.2.2.2`)
services:
# Target a Kubernetes Support
- kind: Service
name: fooبا اعمال این Route تمام درخواستهایی که از IP های 1.1.1.1 یا 2.2.2.2 به سمت ترب میآمد، به سرویس foo ارسال میشد. در اینجا مقدار priority را عدد خیلی بالایی تنظیم کردیم که همیشه به عنوان اولین Route بررسی شود. در نهایت تنها کاری که سرویس foo باید انجام میداد نمایش صفحهی challenge بود. در صورتی که کسی challenge را حل میکرد IP مربوط بهش از داخل این Route حذف میشد. در نتیجه دوباره میتوانست بدون حل کردن challenge به ترب دسترسی پیدا کند. نگرانی دیگر ما، کند شدن پردازش درخواستها به واسطهی اضافه کردن این Route بود. (با توجه به اینکه تعداد IP های غیرمجاز بیش از ۵۰ هزار بود.) طبق بررسی متوجه شدیم که اضافه شدن route کندی چشمگیری در بررسی درخواستها ایجاد نکرده بود.
حذف Traefik
مشکلی که در ادامه با آن رو به رو شدیم افزایش تعداد و حجم حملات DDoS روی ترب بود. بیشتر این حملات در لایهی application بود. بنابراین خط اول مقابله با این حملات Traefik بود. مصرف memory سرویس traefik هنگام این حملات زیاد میشد. طوری که سیستمعامل، process های traefik را kill میکرد. (OOM killer)
از طرفی استفاده از traefik به عنوان ابزاری برای بررسی درخواستها و محدود کردنشون مشکلاتی داشت.
برای اضافه کردن نیازمندی جدید باید کدهای تولید Route را عوض میکردیم. نوشتن و تغییر و نگهداری از این کدها در طول زمان پیچیده و هزینهبر شده بود.
همانطور که گفتیم، ذخیره IP های مشکلدار داخل routing خود traefik انجام شده بود. این routing داخل kubernetes به صورت یک object از نوع IngressRoute ذخیره میشد. هر بار تغییر در لیست IP ها، یک تغییر جزئی در IngressRoute مربوطه ایجاد میکرد و یک نسخهی جدید از object در etcd (پایگاهدادهی kubernetes) ایجاد میکرد. با افزایش نرخ تغییر ipهای غیرمجاز فشار زیادی به دیسک etcd وارد شده و احتمال از دسترس خارج شدن کلاستر kubernetes وجود داشت.
این موارد منجر به تصمیمگیری در جهت مهاجرت از traefik شد.
موارد Envoy, Nginx و HAProxy جزء گزینهها بودند. تعدادی از موارد مانند Caddy به زبان Go توسعه داده شدهاند. با توجه به این که Traefik نیز به زبان Go توسعه داده شده بود، این موارد از لیست حذف شدند.
برای این انتخاب envoy مدرنتر هست. به عبارت دیگر ماهیت پویایی cloud را در نظر گرفته است. در نتیجه به صورت native از تغییرات endpoint ها به صورت dynamic پشتیبانی میکند. (مثل Traefik) به عبارت دیگر، نیازی به ریستارت process ها برای اعمال این تغییرات نیست. ولی در موارد دیگر به صورت native این مورد وجود ندارد. بلکه به صورت third party این قابلیت اضافه شده است. برای مثال Ingress-Nginx Controller در nginx این کار را با استفاده از lua انجام داده است. البته در مورد nginx صرفاً محدود به تغییر endpoint ها است. سایر تنظیمات باید با ریستارت شدن process ها انجام شود. برای HAProxy دو API در نظر گرفتند. در صورتی که نیاز به تغییرات به صورت dynamic باشد باید از این API ها استفاده کنیم. این API ها تغییرات را به صورت persistent اعمال نمیکنند. بعد از هر ریستارت تنظیمات دوباره از فایل خوانده میشود. در نتیجه باید علاوه بر استفاده از API تنظیمات در فایل هم ذخیره شود.
envoy ویژگیهای بیشتری دارد. برای مثال مواردی مثل overload manager, outlier detection, circuit breaker و ... در envoy وجود دارند. در حالی حداقل در نسخهی رایگان Nginx دیده نشده است.
روشهای توسعهی Envoy به مراتب بیشتر است. یکی از مهمتری ویژگیها پشتیبانی خوب از زبات Go است. در حالی که در ngixn/haproxy صرفاً از lua یا زبانهایی غیر از Go میتوان برای گسترش قابلیتهای آنها استفاده کرد. در ادامه مطلب روشهایی که با آنها میتوان envoy را گسترش داد با جزئیات توضیح داده شده است.
درصد commercial بودن envoy کمتر است. به عبارت دیگر کلاً یک نسخه وجود دارد. در این نسخه تمام قابلیتها در دسترس است. برخلاف Nginx که یک سری از قابلیتها فقط در نسخهی Plus آن وجود دارد.
Envoy به عنوان data plane در ابزارهای بزرگی مانند istio و cilium استفاده میشود. در نتیجه تا حدود زیادی میتوان از high performance و reliable بودن آن اطمینان حاصل کرد.
تنها بدی envoy پیچیدهتر بودن تنظیمات آن است. با توجه به این که تقریباً تک تک قسمتهای envoy قابلیت تنظیم از طریق تنظیمات را دارد طبیعی است. با استفاده از Abstraction هایی مانند Envoy Gateway این پیچیدگی تا حد زیادی کم میشود.
تمام این موارد باعث انتخاب Envoy به عنوان reverse proxy اصلی ترب شد.
متولد شدن عنصری به اسم WAF!
همون طور که در قسمتهای قبلی مطرح شد reverse proxy اصلی ترب از traefik به envoy تغییر کرد. با توجه به این که اعمال محدودیت برای IP ها قبلاً توسط traefik انجام میشد، نیازمند این بودیم که به روشی این اعمال محدودیت را به envoy منتقل کنیم. در اینجا پروژهای به اسم WAF ایجاد شد.
از اونجایی که یک Web Application Firewall کارهای زیادی انجام میدهد، اجازه دهید دامنهی مسئولیت WAF که داخل ترب ساختیم را تعریف کنیم. در مرحلهی اول برای جلوگیری از پیچیده شدن سیستم، نیازمندیهای پایهای زیر برایمان مطرح بود.
بتوانیم یک لیست از IP به WAF بدهیم و برای این IP ها challenge نشان دهیم
اگر کاربری یک challenge را حل کرد تا یک مدت برای آن کاربر دوباره challenge را نشان ندهیم
قابلیت دریافت لیست IP ها را داشته باشیم.
امکان bypass کردن درخواست بر اساس یک سری شرایط خاص مثل HTTP Header ها یا path و … را داشته باشیم.
از آن جایی که تمام این عملیاتها در لایهی ۷ (لایهی application) اتفاق میافتاد، ما هم اسم این سیستم را WAF گذاشتیم. ولی یک WAF قطعاً کارهای بیشتری از این چیزی که نوشتیم انجام میدهد. به هر حال، از این جای مطلب تا آخر منظورمان از WAF همین سیستمی هست که تعریف کردیم.
البته یکی از راهها استفاده سیستمهای WAF آماده (مانند SafeLine) است. ولی ترجیح دادیم یک نسخهی ساده و دقیقاً مبتنی بر نیازمندیهای خودمان توسعه دهیم. اینطوری علاوه بر سادگی و تحلیلپذیرتر بودن سیستم، قابلیتهایی که نیاز داشتیم با سرعت و پیشبینیپذیری بیشتر توسعه داده میشدند. برای همین به جای استفاده از ابزارهای آماده، سیستم WAF داخلی ترب را توسعه دادیم.
نقطهی شروع پردازش درخواستها
تمام نیازمندیهایی که مطرح کردیم در یک نیازمندی خلاصه میشوند. امکان این را داشته باشیم که بر سر راه درخواستها کدی را اجرا کنیم. این کد باید درخواستهای ورودی را بررسی و در صورت لزوم روی درخواست محدودیت اعمال کند.
به صورت کلی Envoy شامل تعداد زیادی filter است. (مثل middleware عمل میکنن) درخواست ورودی از تمام این فیلترها رد میشود. در نهایت به یک فیلتر به اسم Router میرسد. این فیلتر درخواست را به سمت سرویس مورد نظر ارسال میکند. (به عبارت دقیقتر Cluster که درخواست باید بهش ارسال بشود را انتخاب میکند. هر Cluster شامل تعدادی endpoint است. هر endpoint ترکیبی از IP و Port است)
به صورت کلی دو راه برای توسعه روی envoy وجود دارد.
توسعهی یک فیلتر جدید
استفاده از فیلترهای موجود
برای توسعهی فیلتر جدید باید کدها را به زبان C++ بنویسیم. اما C++ از زبانهای مورد استفاده در ترب نبود. همچنین باید Envoy را خودمان Compile کنیم. در نتیجه گزینهی آخری هست که باید بهش فکر میکردیم.
از بین فیلترهای موجود، موارد زیر امکان اجرای یک سری کد سر راه درخواستها را دارا بودند:
فیلتر External Processing
فیلتر Golang
فیلتر Lua
فیلتر WASM
فیلتر External Processing اطلاعات درخواست ورودی را در قالب یک درخواست GRPC به سمت یک سرویس ثانویه ارسال میکند. سرویس ثانویه با توجه به اطلاعات ارسال شده میتواند تصمیم مناسب را بگیرد. این فیلتر با توجه به ساختاری که دارد، امکان استفاده از هر زبان برنامهنویسی را میدهد. ولی با توجه به این که in-process نیست (کدها داخل همان process که envoy هست اجرا نمیشود) یک سری overhead مربوط به شبکه و serialization/deserialization را دارد.
در زبان Go میتوان برنامه را بهگونهای کامپایل کرد که بتوان از داخل کدهای C یا C++، توابع Go را فراخوانی کرد. برای این کار، کد Go را با گزینهی -buildmode=c-shared کامپایل میکنیم تا یک کتابخانهی اشتراکی (مثل .so یا .dll) تولید شود و سپس آن را در کد C/C++ فراخوانی میکنیم. داخل envoy از این قابلیت استفاده کردند تا بتوانیم یک filter به زبان Go پیادهسازی کنیم. البته این کار همراه چالشهایی است که در این سند به آنها پرداخته شده است. با توجه به این که این روش in-process هست، performance بالایی خواهد داشت. ولی نکتهی مهم نبود بلوغ کافی برای این فیلتر است.
فیلتر Lua امکان اجرای کد به زبان Lua را فراهم میکند. کدها توسط LuaJIT اجرا میشوند. در نتیجه انتظار کارایی بالایی را داریم. این فیلتر شبیه lua-nginx-module در nginx عمل میکند. ولی تنوع API هایی که در اختیارمان قرار میدهد خیلی کمتر از nginx/openresty است.
فیلتر WASM در واقع استفاده از WebAssembly در دنیای پروکسیها است. امکان توسعه به زبانهایی که از WebAssembly پشتیبانی میکنند را فراهم میکند. منتهی پشتیبانی این زبانها از WebAssembly ممکن است کامل نباشد. مهمترین زبان برای ما زبان Go بود. چرا که در بقیه قسمتها از آن استفاده کرده بودیم. به همین جهت دوست داشتیم تا حد امکان از این زبان استفاده کنیم. ولی در آن زمان امکان استفاده از تمام قابلیتهای زبان Go در فیلتر WASM نبود. برای استفاده از از WASM باید از TinyGo استفاده میکردیم. TinyGo یک compiler برای زبان Go است. در آن زمان امکان استفاده از بعضی کتابخانههای استاندارد برای این compiler نبود. از طرفی این فیلتر به صورت آزمایشی اضافه شده و به صورت فعال در حال توسعه است.
به صورت خلاصه استفاده از Lua با توجه API های محدودی که در اختیارمان قرار میداد گزینهی مناسبی نبود. در WASM نمیتوانستیم از تمام قابلیتهای زبان استفاده کنیم. البته اخیراً پشتیبانی از WASM به مراتب بهتر شده است. در نسخهی 1.24 زبان Go امکان compile کردن برنامه برای WASI فراهم شده است. ولی در آن زمان هنوز این قابلیت را نداشتیم. فیلتر GoLang هنوز به بلوغ کافی نرسیده بود. از طرفی API های پایداری نداشت. به همین جهت تصمیم گرفتیم از فیلتر External Processing استفاده کنیم. البته یک تصمیم نهایی نبود. استفاده از External Processing مشروط به بررسی performance بود. اگر از نظر کارایی مشکلات جدی ایجاد میشد، گزینهی بعدی استفاده از فیلتر GoLang بود.
معماری کلی
پس مشخص شدن گزینهها و ابزارها، معماری سیستم را به شکل زیر تغییر دادیم.
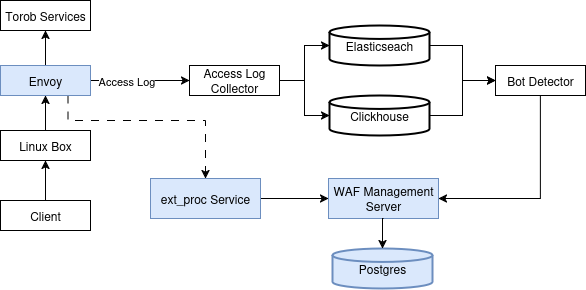
همان طور که اشاره شد envoy یک نسخه از درخواستها را برای ext_proc ارسال میکند. در صورتی که ext_proc اجازهی عبور بدهد، envoy درخواست را به سمت upstream ارسال میکند. ext_proc امکان این را دارد که یک http response برای envoy ارسال کنه. در این صورت envoy درخواست کاربر را به upstream ارسال نمیکند و همان response دریافت شده از ext_proc را به کاربر تحویل میدهد. این response میتواند شامل یک challenge باشد. به اینصورت امکان نمایش challenge برای کاربر فراهم میشود.
سرویس ext_proc به عنوان data plane عمل میکند. به عبارت دیگر قوانین را خودش مدیریت نمیکند. بلکه قوانین را از control plane (در شکل بالا با WAF Management Server شخص شده است) دریافت میکند. سپس بر اساس قوانین دریافت شده از control plane خودش را تنظیم میکند.
پیادهسازی
به صورت کلی خود WAF شامل دو جزء میشود.
data plane
control plane
با توجه به performance و سادگی که زبان Go در مقایسه با سایر زبانها داشت، هر دو component به زبان Go پیادهسازی شده است. از طرف دیگر استفاده از زبان Go امکان switch کردن از یک ابزار به ابزار دیگه (مثلاً استفاده از فیلتر GoLang یا فیلتر WASM) را سادهتر میکرد. همچنین کتابخانههای مختلفی در زبان Go برای پیادهسازی قابلیتهای پچیدهتر WAF وجود دارد. (برای مثال coraza) در صورتی که در آینده نیازمندی تغییر کرد میتوانستیم از این موارد استفاده کنیم.
برای سادگی و سرعت در توسعه، ارتباط بین data plane و control plane به صورت REST پیادهسازی شده است. قوانین به صورت دورهای (برای مثال در بازههای ۲ ثانیهای) از control plane دریافت میشوند. تمام قوانین به صورت immutable هستند. به عبارت دیگه حتی اگر یکی از قوانین در پایگاهداده تغییر کند، تمام قوانین برای data plane ارسال میشود. این تصمیم در جهت سادهتر شدن کدها و جلوگیری از race condition های پیچیده در زمان بهروزرسانی قوانین گرفته شد.
همانطور که داخل شکل مشخص است envoy با ext_proc در ارتباط است. این یک ارتباط GRPC هست. برای این ارتباط از unix domain socket استفاده کردیم. اولین دلیل این بود که میخواستیم هیچگونه ارتباط شبکهای وجود نداشته باشد. به عبارت دیگر نمیخواستیم ترافیک GRPC از node که envoy روی آن قرار دارد خارج شود. به اینصورت اختلالات جزئی شبکه اثری بر کار سیستم نمیگذارد. از طرف دیگر راهحل سرراستی برای اضافه کردن auth به سرویس ext_proc نداشتیم، به همین جهت باید ارتباطها به صورت local تعریف میشدند تا ریسکهای امنیتی آن را کاهش دهیم. تصمیم استفاده از unix domain socket به جای loopback جنبهی فنی نداشت. به عبارت دیگر هیچگونه تفاوت قابل مشاهدهای بین آنها از نظر performance وجود نداشت. این تصمیم بیشتر به خاطر config کردن راحتتر گرفته شد. این نکته قابل ذکر است که ما از Envoy Gateway به عنوان control plane برای envoy استفاده میکنیم. استفاده از loopback به عنوان external processor نیازمند تغییرات بیشتری نسبت به استفاده از unix socket ها داشت.
در بسیاری از CDN ها و ابزارهای WAF ما یک لیستی از قوانین داریم. تمام این قوانین از یک ساختار مشترک استفاده میکنند. برای مثال به قوانین زیر توجه کنید.
Rule 1: host = torob.com and path = '/test/' -> Block
Rule 2: client_ip = '1.1.1.1' -> Allow
Rule 3: client_ip = '0.0.0.0/0' -> Blockدر این قوانین یک سری operator پایه مثل «مساوی» وجود دارد. سپس با استفاده از عبارتهای منطقی مانند and و or قوانین پیچیدهتری را میتوان ساخت. ولی در ترب از این روش استفاده نکردیم. بیشتر نیازمندی ما اعمال محدودیت روی یک تعداد IP بود. در نتیجه نیازی به این قوانین پیچیده وجود نداشت. از طرفی سادگی و قابل فهم بودن سیستم و سرعت پردازش دادهها برایمان اهمیت زیادی داشت. به همین جهت قوانین را به دو دستهی deny_rule و allow_rule تقسیم کردیم. در دستهی deny_rule فقط IP کاربر وجود داشت. در دستهی allow_rule علاوه بر IP، موارد مهمتر مانند host, path و header قرار داشت. در صورتی که IP درخواست ورودی در deny_rule وجود داشت و در قوانین allow_rule یک match پیدا نشود، درخواست باید محدود شود. در غیر اینصورت اجازهی عبور داده شود. با توجه به این که اکثر درخواستها، کاربران عادی هستند، اکثر درخواستها با یک مرتبه IP lookup اجازهی عبور میگیرند. تعداد خیلی کمتر درخواستها به مرحلهی دوم (بررسی قوانین allow) - که بار پردازشی بیشتری را میگیرند - میرسند.
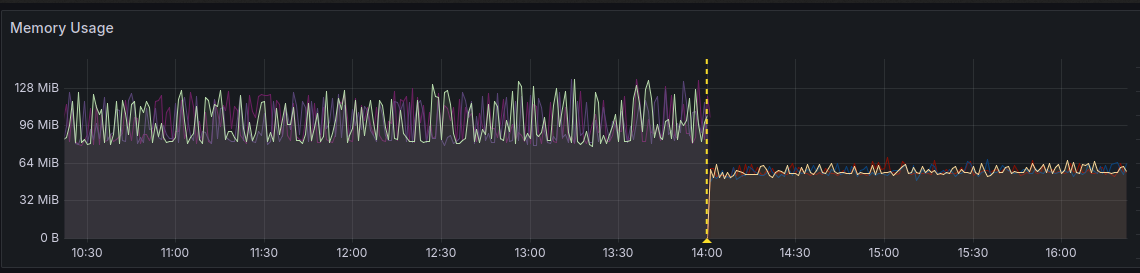
نرخ تغییرات deny_rule ها خیلی زیاد است. (تقریباً هر ثانیه تغییر میکنند) از طرفی گفتیم که با هر تغییر، تمام قوانین برای data plane ارسال میشود. در صورتی که تعداد IP ها داخل deny_rule زیاد باشد، حجم زیادی از دادهها باید serialize/deserialize شوند. همچنین هر بار باید trie مورد نظر برای IP lookup از اول ساخته شود. برای حل این موضوع از فرمت mmdb استفاده کردیم. این فرمت، فرمت اصلی استفاده شده در پایگاهدادههای MaxMind است. این فرمت در واقع یک درخت است که به صورت binary داخل یک فایل ذخیره شده است. به همین دلیل کوئری زدن را خیلی سریع میکند. جزئیات این فرمت در این لینک توضیح داده شده است. با استفاده از این فرمت یک بار درخت را میسازیم و سپس آن را در اختیار data plane قرار میدهیم. چیزی که تحویل data plane میشود یک فایل هست. در نتیجه هیچگونه serialization/deserialization ندارد. از طرفی چون درخت از قبل ساخته شده است دیگر نیازی به ساخت مجدد ندارد و بلافاصله بعد از دریافت آماده استفاده است. بعد از این تغییر میزان مصرف Memory مربوط به data plane از حدود 128MB به حدود 64MB تغییر کرد.
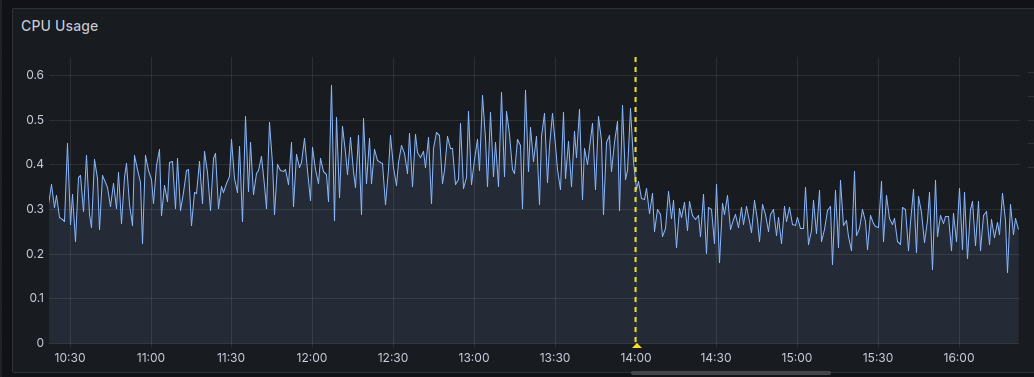
همچنین میزان مصرف CPU مربوط به data plane از حدود 500m به 300m تغییر کرد:
استقرار
با توجه به اینکه از تاثیر استفاده از این سیستم روی response time سرویسها مطمئن نبودیم، ابتدا این سیستم را برای یک سرویس تستی فعال کردیم. کار این سرویس تستی برگرداندن کد ۲۰۰ بود. در نتیجه پردازش زیادی لازم نداشت. به همین جهت میزان latency ایجاد شده توسط سیستم توسعه داده شده به خوبی قابل مشاهده است. با نرخ حدود ۲۰ هزار درخواست در ثانیه برای این سرویس درخواست ارسال کردیم. نتایج به صورت زیر ثبت شد:
Latency distribution:
10% in 0.0039 secs
25% in 0.0044 secs
50% in 0.0051 secs
75% in 0.0061 secs
90% in 0.0075 secs
95% in 0.0084 secs
99% in 0.0109 secs همانطور که دیده میشه برای p99 زمان پاسخگویی 10ms بود. از طرفی این زمان مربوط به جمع زمانها (زمان پاسخگویی خود سرویس + WAF) بود. اگر فرض کنیم که خود سرویس زمان نمیگیرد، در بدترین حالت انتظار اضافه شدن 10ms به زمان پاسخگویی درخواستها را داشتیم.
با توجه به نتیجهی این آزمایش - که مشخص شد احتمالاً latency زیادی ایجاد نمیشود - سعی کردیم روی یک سرویس واقعی آزمایش کنیم. برای این آزمایش یکی از minio ها انتخاب شد. نرخ درخواستها روی این minio حدود ۱۲۰۰ درخواست در ثانیه بود. نمودار زیر مربوط به response time همین minio در زمان فعال شدن WAF روی minio است.
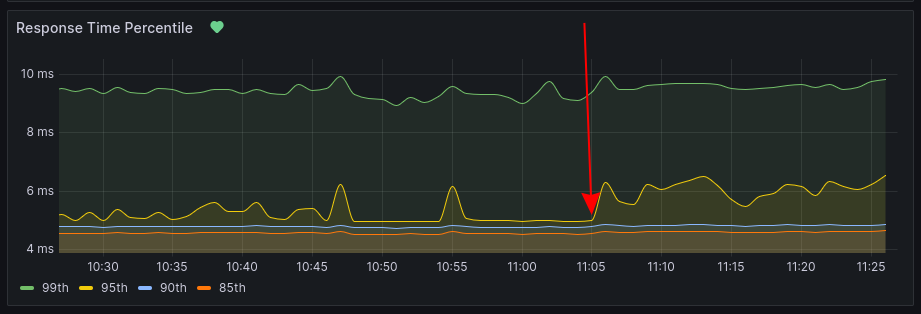
همان طور که دیده میشود p95 حدود 1.5ms افزایش داشته است. در حالی که در بقیه موارد تغییر قابل توجهی دیده نمیشود. با توجه به این آزمایشها در مجموع جمعبندی این بود که میزان افزایش response time بعد از فعال کردن WAF خیلی ناچیز است. در نتیجه روی API اصلی این سرویس فعال شد.
بعد از فعال شدن روی API اصلی همانطور که انتظار میرفت افزایش قابل ملاحظهای در response time دیده نشد. با این حال برای حالتهای پیشبینی نشده، envoy به گونهای تنظیم شد که حداکثر 30ms منتظر جواب از ext_proc باشد. در صورتی که بیشتر از این زمان طول کشید، به درخواست اجازهی عبور داده میشود. در نتیجه حداکثر میزان latency ایجاد شده عدد 30ms خواهد بود.
جمعبندی
مسیر طراحی و پیادهسازی WAF در ترب، سفری بود از ابزارهای آماده و متنوع تا ساخت یک سیستم اختصاصی و متناسب با نیازهای خودمان. در ابتدا با راهحلهایی مانند OPNsense و iptables تلاش کردیم تا جلوی درخواستهای مشکوک را بگیریم. این روشها ساده و سریع بودند، اما در مقیاس بالا مشکلاتی مثل کندی، دشواری در عیبیابی و محدودیت در نمایش خطا به کاربر داشتند.
در ادامه، با استفاده از Traefik سعی کردیم کنترل ترافیک را به لایهی ۷ منتقل کنیم تا بتوانیم رفتار کاربران را دقیقتر تحلیل کنیم و در صورت نیاز، با نمایش چالش (challenge) از صحت درخواستها مطمئن شویم. این روش هر چند مزیتهایی داشت، اما در برابر رشد ترافیک و حملات DDoS پایداری کافی نداشت و نگهداری از قوانینش در مقیاس بالا سخت بود.
در نهایت، با مهاجرت به Envoy و توسعهی سیستمی بر پایهی فیلتر External Processing، امکان پیادهسازی WAF برای ترب فراهم شد. در این معماری جدید، وظایف مدیریت قوانین و اعمال قوانین از هم جدا شدند (control plane و data plane)، قوانین با ساختاری ساده ولی کارآمد مدیریت میشوند، و عملکرد سیستم در تستها نشان داد که افزایش زمان پاسخگویی ناچیز و قابل قبول است.
استفاده از فرمت mmdb برای ذخیرهی قوانین IP باعث شد تا مصرف منابع به شکل چشمگیری کاهش یابد و انتقال قوانین از control plane به data plane سریعتر انجام شوند. به این ترتیب، WAF جدید توانست بدون فدا کردن سرعت یا پایداری، جایگزین مناسب و قابل توسعهای برای زیرساختهای قبلی باشد.
در مجموع، این تجربه برای تیم ما تنها ساخت یک ابزار امنیتی نبود، بلکه گامی در جهت یادگیری، بهینهسازی و ساخت زیرساختهایی بود که در برابر چالشهای آینده مقاومتر باشند.
فرصتهای شغلی ترب
اگر به تکنولوژیهای نوآورانه علاقه دارید و دوست دارید در توسعه یک موتور جستجوی خرید پیشرو نقش داشته باشید، تیم مهندسی ترب به دنبال افراد باانگیزه و خلاق است!
مشاهده فرصتهای شغلی
مطلبی دیگر از این انتشارات
۷ تغییر برای ۸ برابر شدن سرعت همگامسازی دیتابیس جستجوی تصویری
مطلبی دیگر از این انتشارات
بهروزرسانی پایگاهدادهی اصلی ترب
مطلبی دیگر از این انتشارات
واگذاری یک گردشکار پیچیده به هوش مصنوعی مولد